

NuCaptcha is the first widely deployed video captcha scheme. Since Technology Review interviewed me about NuCaptcha in October 2010, I have been working on evaluating its security and usability. In this blog post, I will discuss how we are able to break the current version of NuCaptcha with 90% success and also discuss a possible approach to fix them.
Our fix is based on a new design principle called tracking resistance . Intuitively tracking resistance means you had object that have the same properties than the real captcha so the algorithm don’t know which object in the video he should track. When successfully implemented, tracking resistance makes video captcha secure against vision/machine learning attacks and more secure than standard text-based captchas. I have been working on NuCaptcha security with many people over the last year and half, including Matthieu Martin, Shang Ping, Jonathan Aigrain, Mike Bailey and John Mitchell.
Responsible disclosure
Before getting started, it is important to mention that this post is a responsible disclosure: I have been in contact with the CEO of NuCaptcha for a couple of months now and have shared with him the result of our research way ahead of time, so they had plenty of time to get ready for this post (you can read their answer here) I also want to emphasize that the goal of this post is not to demo another cool attack (even though the algorithm is pretty nifty). Rather, I want to start an open discussion on the viability of our tracking resistance principle and to allow everyone to contribute to making video captchas a viable alternative to more traditional captcha schemes.
Feedback Welcome
While discussing ongoing research (that is, before a research paper is accepted or submitted) is unorthodox in the security community, the numerous interactions I’ve had with various companies over the last 3 years made me realize many people rely on research results to design captchas. In this context, it is our duty to provide them the best and most secure design guidelines possible. I strongly believe in the example set by the cryptography community, that the best security is achieved through an open process and not with secrecy or isolation. Accordingly, this post summarizes our understanding of video captcha security and the reasoning that leads us to believe that tracking resistance is the best principle to make video captcha secure. The most difficult part of this research turned out not to be breaking NuCaptcha, which I’ve known how to do since December 2010, but rather to come up with the right abstraction to explain why video captchas might offer better security that image captchas and to synthesize where the extra security comes from. With this in mind let’s get started on how to break NuCaptchas before discussing how to make them secure.
The NuCaptcha Scheme
There are currently two different versions of NuCaptcha: a ‘simple’ version and the ‘standard’ version. The simple version looks like this:

The standard version looks like this:


As visible in the screenshot, the standard version differs from the simple version by a text animation from right to left. The user is then asked to enter the last word in the input box in the standard version. This scheme has multiple levels of security: In its easiest version the letters of the last word are in red, in the hard version the letters are in black and more heavily distorted. According to the site documentation, NuCaptcha uses a reputation algorithm to decide which version you get. Under the hood the NuCaptchas are short video files that contains about 500 frames.
Which version to evaluate?
Since our technique successfully breaks the simple and the standard version of NuCaptcha, I am going to stick with the standard version because I believe that motion is the key feature to create a secure video captcha. To keep things fair, we are also going to focus on breaking the hard version and not rely on any of the advantages provided by having the letter in red or having them less distorted.
Background customization
NuCaptcha allows users to choose between various background to customize their captchas. However, as we showed at CCS last year (available here) in our paper on breaking and securing text captchas, removing the background is fairly easy with the right algorithm so we are going to stick with the default one. Regardless of the background chosen, but our attack still applies.
Attack algorithm overview
Overall, breaking a NuCaptcha captcha is done by accomplishing the 5 phases depicted in the diagram below. The attack algorithm assumes NuCaptchas that have been converted into frames. This step can be trivially executed using off-the-shelf software, so we will not discuss it here.
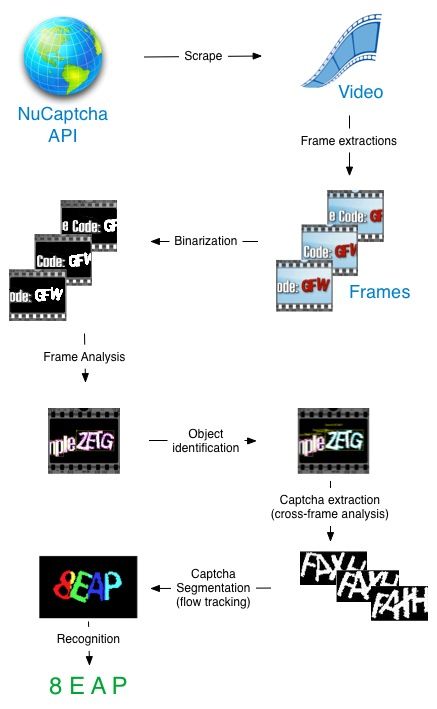
The pre-processing phase involves removing the background and binarizing the captcha in black and white so it is easier to process. The frame analysis phase is then used to find the object in each frame can potentially be the captcha. The cross-frame analysis phase combines the frame analysis results to isolate the set of frames where the actual captcha is present. The segmentation phase aims at separating the captcha letters. As we will see there are a couple of ways to do thishaving multiples distortions of the same captcha actually gives us an opportunity to be more efficient at segmentation than with a standard captcha. Finally, the recognition phase is used to recognize each letter individually using a machine learning algorithm.
How does it compare to standard text-based captchas
Compared to breaking image-based captchas, attacking video captchas is both harder and easier. It is harder because motion tracking is necessary to isolate the frames that contains the actual captcha. It is easier because being able to analyze multiple copies of the same captcha can boost the accuracy of the segmentation phase. Since the pre-processing part and the recognition part are very well understood and use well-known techniques, I am going to skip them to keep this blog post shorter. If you are interested in the subject or need a refresher, please read my paper on attacking image-based captchas (available here).
Finding the captcha
Before we can attempt to segment the captcha, we first need to find the frames in which it appears. We assume that each NuCaptcha has a different starting point in the animation, as we want our attack to be robust and not to rely on easily fixable features. Our first task is thus to isolate the frames that contain the captcha itself, and within these frames isolate the captcha from other words that appear. To achieve this we track and analyze the words moving in the captcha using image and motion tracking. Our captcha isolation technique works backward and is done in two steps: First we isolate the most interesting object in each frame (see next section), then we track theses objects across multiple frames and keep the set of 50 frames that contain the overall most interesting object.
Frame analysis: finding the most interesting object
We relying two type of image analysis to isolate the most interesting object in each frame: a bounding box shape analysis, and an interest points (SIFT algorithm) density evaluation. An example of a frame where the object bounding boxes (the yellow squares), and object interests points (purple crosses) are computed is visible on the screenshot below:

Based on these features, we found two ways to select the most interesting object: First, we look at the bounding box shape ratio width/height. Because the captcha is 4 letters long, we use a heuristic that the bounding box must have a width/height ratio of greater than 1. We then discard every bounding box that is above or below certain thresholds, as we roughly know what the expected ratio is after looking at a couple of captchas. Second, we look at the SIFT (Scale-invariant feature transform) interest points density by bounding box. As visible on the screenshot above, the captcha bounding box contains more interesting points that the other boxes. This is explained by the fact that the captcha letters are rotated independently and therefore have more ‘edges/corners’ than straight letters. The fact that the letters are rotated also implies that for the real captcha the interests points are scattered all over the box. On the other boxes the interest points are mostly nears the edges because the letters are straight. We aggregate these two observations (more points, more scattering) into a density metric D that will be used to select the most interesting object. The metric D is computed as follows: D = Sum(1/distance(p_1, box_center)) where distance is the Euclidean distance and p_1 is each interest point. Basically, D calculates a weighted-sum of all the interest points by giving more weight to the interest points closer to the center of the box. Combining these two techniques allow us to isolate the most ‘interesting’ object in each frame, by removing the objects below or above the bounding box thresholds and picking up the object for which D is the highest. The result of this selection algorithm for our example fame is visible on the screenshot below (Den being the value of the metric D for the given box):

Cross-frames analysis: finding the captcha
Being able to isolate interesting objects is not good enough because in some frames the captcha will not be present. To isolate the set of frames where the most interesting object is the real captcha, we use the features extracted during the frame analysis step to do a “cross-frame analysis.” Our cross-frame algorithm works by computing a sliding window over the density metric D on 50 frames. As visible on the screenshots below, where the D value of the window is represented in the red curve, there is a clear spike when the captcha is displayed. So all we have to do is keep the highest spike (which encompass 50 frames) and discard the remaining frames.
Segmenting the captcha
The previous step identified 50 frame containing the captcha, giving us 50 instances of the same captchas that are slightly different (each letter is being animated independently). Here is an example:

We can exploit these multiple variations of the same captcha in three different ways to help segment the captcha into individual letters. First we can try to find an instance where all the letters are disjoint, making the segmentation trivial with a clustering algorithm. While we did found some instances where this is the case, this is not a good approach as it is unreliable and can be patched very easily. The second approach is to try Decaptcha (our captcha tool) on every instance, and uses a voting decision to select the most probable answer. Using this approach, Decaptcha gives a 83% success rate on NuCaptchas. Here is an example of some of the clusters we have on a given NuCaptcha. It can be seen that than some of them are better segmented than others and therefore easier to recognize.

It is likely possible to improve the effectiveness of this approach by factoring the confidence of the classifier in the voting procedure, but since the results with simple voting were already good enough to prove NuCaptcha vulnerable, we ended up not pursuing this direction. A third approach to get close to 100% success rate is to use motion tracking (optical flow) to segment the letters. This approach uses a two-step algorithm. First, we compute the interest points in each frame and then track them across frames. You can see an example of this step on the screenshot below:
Second, we compute a distance matrix (using a RANSAC algorithm) to analyze which interest points move together, defined as their relative distance staying almost constant. Each group of points that moves together makes up a cluster that represents a letter. We can use these points to know where each letter starts and ends and to perform segmentation, which we show in the screenshots below. Since matching corresponding interest points between frames is never perfect, sometime we have very good results and sometime bad ones. However, since we track letter movements between pair of frames (the frame and the frame + 5) we have a lot of candidates to choose from, and we only need one good match to be successful. This discrepancy between the quality of the matches is illustrated on the screenshot below. The left side depict an example where the tracking has generated 6 clusters that are not very accurate. The example on the right shows a successful clustering based on the distance matrix data. Even though the E, A, and, P are collapsed we are able to almost perfectly separate them using the distance matrix.
Synthesizing the problem
To summarize, animating the captcha allows the attacker to do a “differential” analysis that helps the attack be more efficient. On the other hand, not animating the captcha is equivalent to having a static (text-based) captcha renders moot any security advantage of using a video captcha.
Toward secure video captcha
So are video captchas worthless? No, but it requires a lot of out of the box thinking for us to find a way out. It took us significantly longer to understand the root of the problem and how to solve it than to break the current NuCaptcha scheme. Once we have accepted the fact that the segmentation resistance for video captchas will be equivalent or lower than a standard text-based captcha(as explained above), it becomes clear that the extra-security provided by using a video captcha needs to come from somewhere elseWe have to find a hard vision problem to rely upon. Trying to prevent the computer from finding moving objects using a ‘confusing/moving background’ is a lost cause. The computer vision field has devised very efficient algorithms (optical flow algorithm) that are likely to destroy any attempts in this direction. On the other hand, it seems possible to make the isolation of the correct moving object very difficult. What we need to do is to remove every discriminative feature (or invariants as Jeff Yan calls them) that the attacker can use to tell apart decoy moving objects and the real captchas. For example our attack relies on two discriminative features to isolate the captchas: the number of interest points and the shape of the bounding box. Both of these features can be nullified by adding (moving) decoys that exhibit the same properties.
NuCaptcha Response
As I said in the introduction, we notified NuCaptcha on November 21st, 2011 informing them we had an attack against their current scheme and iterated with them until December 15th 2011. On February 7th we wrote this blog post and shared it with them. At this time, they provided us an official answer that you can read here. Their answer contains two mains points regarding the attack. First on page one, they state, that they have a harder version that add more distortions and where the letters are more crowded. When scraping their API, we emulate the behavior of a real bot by aggressively timing our requests. While we believe we got the version that a standard attacker might get (which is already harder than the version displayed on site), we have not evaluated the hard version referenced in their response. With respect to the difficulty of their hard CAPTCHA, I don’t believe that these heavier distortions are an efficient defense because even if the letters are more crowded, it should not impact an optical flow algorithm used to separate the letters. Further, I believe the heavier distortions should not be an issue for the recognition phase as it is well known since 2005that computers beat human when it comes down to recognizing a single heavily distorted character.

The solution proposed by NuCaptcha. Image taken from their response.
Regarding their fix, they propose adding inter-frame manipulation (see screenshot above ) which should mess-up our optical flow analysis by throwing of our distance matrix. I won’t be able to characterize the effectiveness of this technique until they roll out their changes and I can test it. My guess is that it is somewhat less effective, based on the fact than in cryptography adding noise to prevent side-channel attacks has been known to be ineffective (The canonical example being the differential power analysis attack (DPA) by Paul Kocher), but again will withhold judgement until we can test.
Toward secure video captcha
It is likely that there are features other than the two we used that can be abused by an attacker to break tracking resistance. This is why, following the good practices pioneered by the cryptography community, we decided to ask for your help to find them. This post openly discusses what we already know about video captcha security. We hope this is the first step in an evaluation process dedicated to make the video captcha tracking resistance a viable option. I will also discuss this attack in my upcoming RSA talk about captchas in February, so if you are around, I would be happy to discuss it.
Thank you for reading this post till the end! If you enjoyed it, please don’t forget to share it on your favorite social network so that your friends and colleagues can enjoy it too.
To get notified when the next post is online, follow me on Twitter, Facebook, Google+. You can also get the full posts directly in your inbox by subscribing to the mailing list or my RSS feed.


